Why Measuring AI Visibility Is Harder Than SEO
Most brands have no idea whether they show up in AI-generated answers. Not a vague sense. Literally no idea. With traditional search, you could check your rankings. Type a keyword into Google, see where you land, track it over time. The system was legible. Imperfect, but legible. AI engines don't work that way.
There are no rankings. There's no fixed position on a results page. When someone asks ChatGPT, Gemini, or Perplexity a question about your category, the answer they get depends on the prompt, the model version, the context window, and sometimes what feels like the AI's mood that day.
So how do you actually measure whether your brand is visible in these systems?
It's possible. But it requires a different approach than anything most marketing teams are used to. Try to do it manually without structure and you'll burn hours and still end up with unreliable data.
Let me walk through how to do it right.
What Makes This So Different From Tracking Google Rankings?In SEO, you had a relatively stable system. A keyword mapped to a set of results. Those results shifted over time, but the structure was predictable. Tools could crawl it. You could benchmark.
AI answers have none of that stability. What makes measurement fundamentally harder comes down to a few specific things.
No rankings. There's no "position 3" in a ChatGPT response. Your brand is either mentioned or it isn't. And if it is mentioned, the framing matters as much as the inclusion. Being listed as "another option to consider" is very different from being named as the recommended solution.
No standardized outputs. Ask the same question to the same model twice and you might get different answers. The models are probabilistic. They don't return a fixed result set. This means a single test tells you almost nothing about your actual visibility.
Prompt variability. The way someone phrases their question changes the answer dramatically. "What's the best CRM for small teams?" and "Which CRM should I use if I have under 10 people?" can produce completely different brand mentions. There's no canonical query the way there's a canonical keyword.
This is why I keep telling people that AI visibility isn't a minor variation on SEO. It's a different measurement problem entirely. If you want to understand the full scope of what's changed, our AI visibility metrics framework lays out the conceptual shift in more detail.
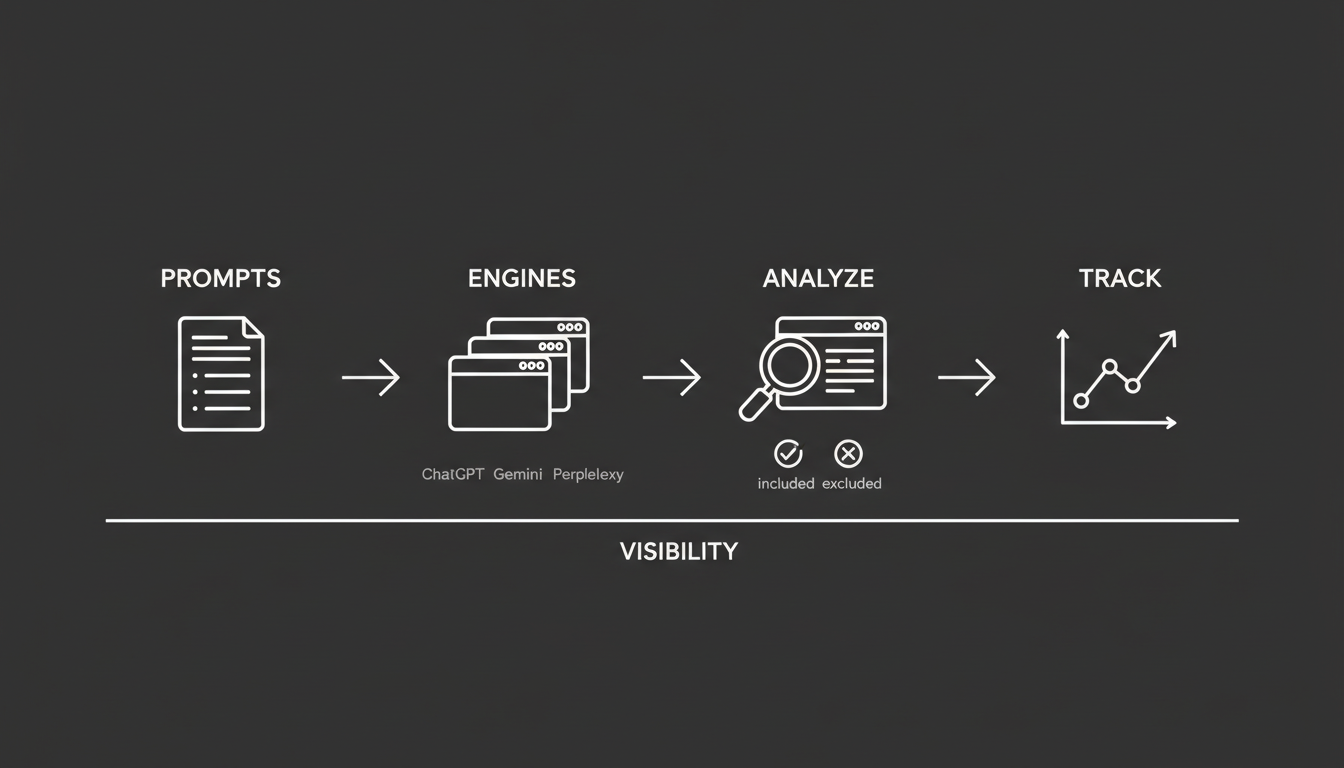
Step 1: Define the Right Prompts
You can't measure what you don't test. And you can't test effectively if you're using the wrong prompts. Most people start by typing their brand name into ChatGPT and seeing what happens. That's backwards. Your customers aren't searching for you by name in AI engines. They're describing problems, asking for recommendations, comparing options.
You need to build a prompt library that mirrors how real buyers actually ask questions. A few categories matter most here.
Category prompts. These are the broad questions about your space. "What are the best project management tools?" or "What software do marketing teams use for analytics?" These tell you whether you exist in the AI's mental model of your category at all.
Comparison prompts. These pit you directly against competitors. "How does [Your Brand] compare to [Competitor]?" or "Should I use [Brand A] or [Brand B] for [use case]?" These reveal not just whether you're mentioned, but how you're positioned relative to alternatives.
Problem-based prompts. These start from the buyer's pain point, not your product category. "How do I reduce customer churn for my SaaS product?" or "What's the best way to automate my sales outreach?" These are the highest-signal prompts because they match real buying intent. If the AI recommends your product when someone describes a problem you solve, that's meaningful visibility.
Build at least 10 to 15 prompts across these categories. More is better. The goal is coverage, not perfection.
One thing I've learned from 25 years of watching technology shifts: the companies that measure early, even imperfectly, build an information advantage that compounds. The ones that wait for perfect tools fall behind.
Step 2: Test Across Multiple AI Engines
Here's where people get it wrong. They test in ChatGPT, see their brand mentioned, and assume they're covered. That's like checking your Google ranking and assuming you rank the same on Bing and DuckDuckGo. Except the gap between AI engines is much wider than the gap between traditional search engines ever was.
ChatGPT, Gemini, and Perplexity use different models, different training data, different retrieval methods, and different answer structures. A brand that shows up consistently in Perplexity, which pulls from live web sources, might be completely absent from ChatGPT's responses, which rely more heavily on training data and increasingly on browsing and plugins.
Why does this matter? Because your customers aren't all using the same engine. The distribution is fragmenting fast. If you only measure one engine, you're seeing maybe a third of the picture. For each prompt in your library, test it across at least ChatGPT, Gemini, and Perplexity. Note the differences. They'll be big.
We've written about the multi-engine visibility gap specifically because this is one of the most common blind spots we see. Brands that look strong in one model can be invisible in another.
Step 3: Analyze the Answers
Running the prompts is the easy part. Making sense of the results is where the real work happens. Don't just check whether your brand name appears. That's table stakes. You need to evaluate a few dimensions of every response.
Inclusion vs. exclusion. Is your brand mentioned at all? If not, that's your baseline. You're invisible for that prompt in that engine. That's important data, even if it's not the data you wanted.
Positioning language. When your brand is mentioned, how is it described? Is it the primary recommendation? One option among many? A budget alternative? The language the AI uses to frame your brand shapes how the reader perceives you. "Company X is a popular choice" carries very different weight than "Company X is widely considered the industry leader."
Pay close attention to qualifiers. Words like "however," "although," and "but" often signal that the AI is about to undercut a recommendation. If your brand gets mentioned and then immediately followed by a caveat, that's not great visibility. That's visibility with a warning label.
Competitor mentions. Who else shows up in the same answer? This tells you who the AI considers your competitive set. Sometimes it matches your actual competitive set. Sometimes it doesn't. Both are useful information.
I've seen cases where a brand's biggest competitor in the real market barely exists in AI answers, while a smaller player dominates the recommendations. The AI's competitive map and your market's competitive map aren't the same thing. Knowing where they diverge gives you an edge.
Step 4: Track Patterns Over Time
A single round of testing gives you a snapshot. Snapshots are useful, but they're not strategy.
AI models update. Training data changes. Retrieval systems evolve. A brand that's invisible today might appear next month because the model ingested new content. A brand that's recommended today might disappear after a model update.
This is why one-time testing is insufficient. You need to establish a cadence. Monthly at minimum. Weekly if AI visibility is a strategic priority for your business.
What you're looking for isn't any single result. It's trends. Is your mention rate increasing or decreasing? Are you gaining ground in problem-based prompts? Are competitors appearing more frequently in comparison prompts?
The pattern is the signal. Individual results are noise.
Document everything. Date-stamp your tests. Record the exact prompt, the engine, the model version if you can identify it, and the full response. This creates the historical record you'll need to understand what's actually changing and why.
I've just walked you through a legitimate measurement approach. It works. But I want to be honest about where it breaks down.
Consistency is nearly impossible to maintain. Manual testing means a human running prompts, reading responses, and making judgment calls about positioning language. Different people will interpret the same response differently. The same person might interpret it differently on a Tuesday than a Friday. This isn't a criticism of anyone's judgment. It's just the nature of subjective analysis at scale.
Historical tracking requires discipline that most teams don't sustain. The first month of manual tracking is energizing. By month three, it's a chore. By month six, the spreadsheet is a mess and nobody remembers the exact methodology from the first round. I've seen this pattern play out dozens of times across different measurement challenges over my career. Manual processes that require ongoing discipline almost always degrade.
Scalability is the real killer. If you have 15 prompts across 3 engines, that's 45 individual tests per round. Weekly testing means 180 tests per month. Each one requires running the prompt, reading the full response, categorizing the result, and logging it. For a single brand. If you're tracking competitors too, multiply because of this.
Most marketing teams simply can't sustain that workload alongside everything else they're responsible for. The measurement effort either shrinks to a token exercise or gets abandoned entirely.
Manual measurement is possible and it's a great starting point. But it hits a ceiling fast.
So What Actually Scales?
The answer is systems. Not manual heroics.
You need automated prompt testing, structured response analysis, cross-engine comparison, and historical tracking that runs without someone remembering to do it every week.
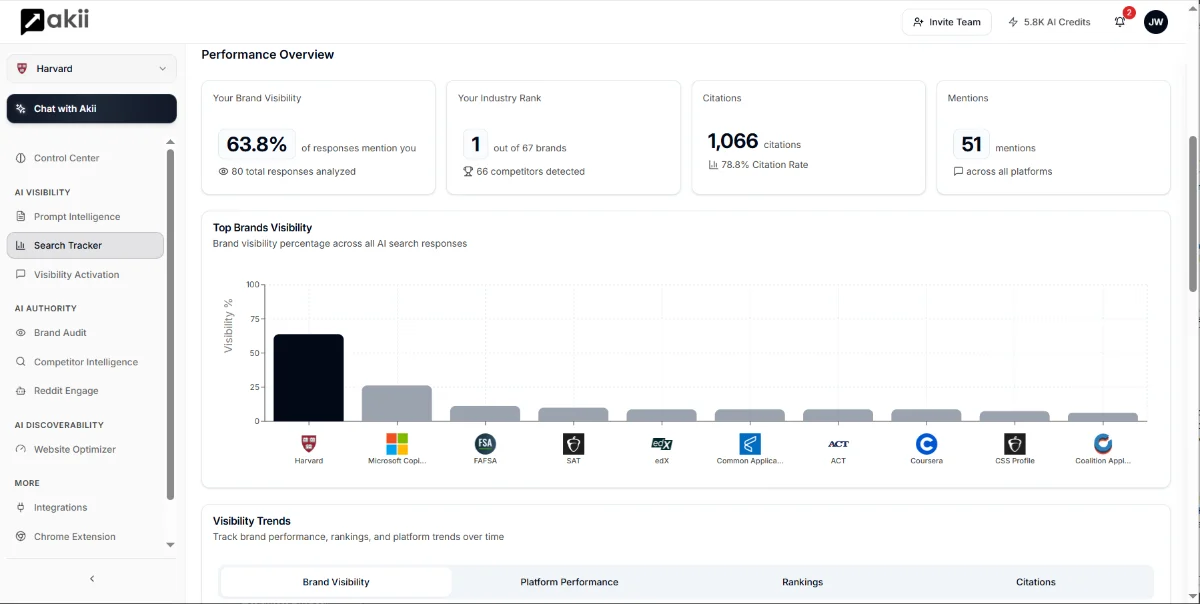
This is exactly the problem we built Akii's AI Search Tracker to solve. Not because manual measurement is wrong, but because it's unsustainable for any brand that takes this seriously.
The brands that will own AI visibility over the next few years aren't the ones with the best one-time audit. They're the ones with continuous measurement feeding continuous improvement.
If you're just starting out, the manual approach I described above is genuinely valuable. Run through it once. Get your baseline. Understand the territory you're operating in.
But if you're planning to compete for AI visibility as a core part of your marketing strategy, and you should be, you'll need to move beyond manual testing faster than you think.
The shift from traditional search to AI-generated answers is the biggest change in how buyers find products since Google itself. Measuring your position in that shift isn't optional. It's the foundation everything else gets built on.
Start measuring now. Even imperfectly. The data you collect today becomes the baseline that makes every future decision smarter.