GEO Metrics Sound Familiar. That's Exactly the Problem.
If you've been in marketing long enough, you develop a reflex. You see a dashboard with scores, rankings, and trend lines, and your brain slots it into a familiar category. You think: I know what this is. I know how to act on it.
That reflex is going to cost people real money in GEO.
I've watched this pattern repeat across multiple technology cycles over 25 years. A new category emerges, borrows the language of whatever it's replacing, and everyone nods along because the words feel safe. The companies that confused familiarity with understanding end up six months behind the ones that asked harder questions early.
Generative Engine Optimization is real. The shift in how people discover brands through AI is real. But the metrics being sold around it right now deserve more scrutiny than most people are giving them.
Not because they're fake. Because they don't mean what you think they mean.
Wait, There's No Real Data From AI Platforms?
This gets glossed over in almost every GEO pitch, and it's the single most important thing to understand before you spend a dollar on any of it.
No major AI platform provides official analytics for brand mentions, citations, or visibility inside real user conversations.
Let that settle for a second.
ChatGPT conversations are private. Google AI Overviews are blended into Search Console with no dedicated reporting. Claude, Gemini, and Microsoft Copilot offer nothing at the brand level. Perplexity shows citations, but detailed analytics are limited to select publisher partners.
There is no feed of real prompts. There is no log of brand mentions across conversations. Nobody has access to this data. Not your agency. Not your GEO tool. Not you.
So where do all those visibility scores come from?
Vendors create prompt sets, run them against AI models, and measure how often your brand shows up in the responses. That's the foundation of nearly every GEO metric on the market right now.
Is that useful? It can be. Is it the same as knowing how real users encounter your brand in AI? Not even close.
Why Do These Metrics Feel So Familiar If They Mean Something Different?
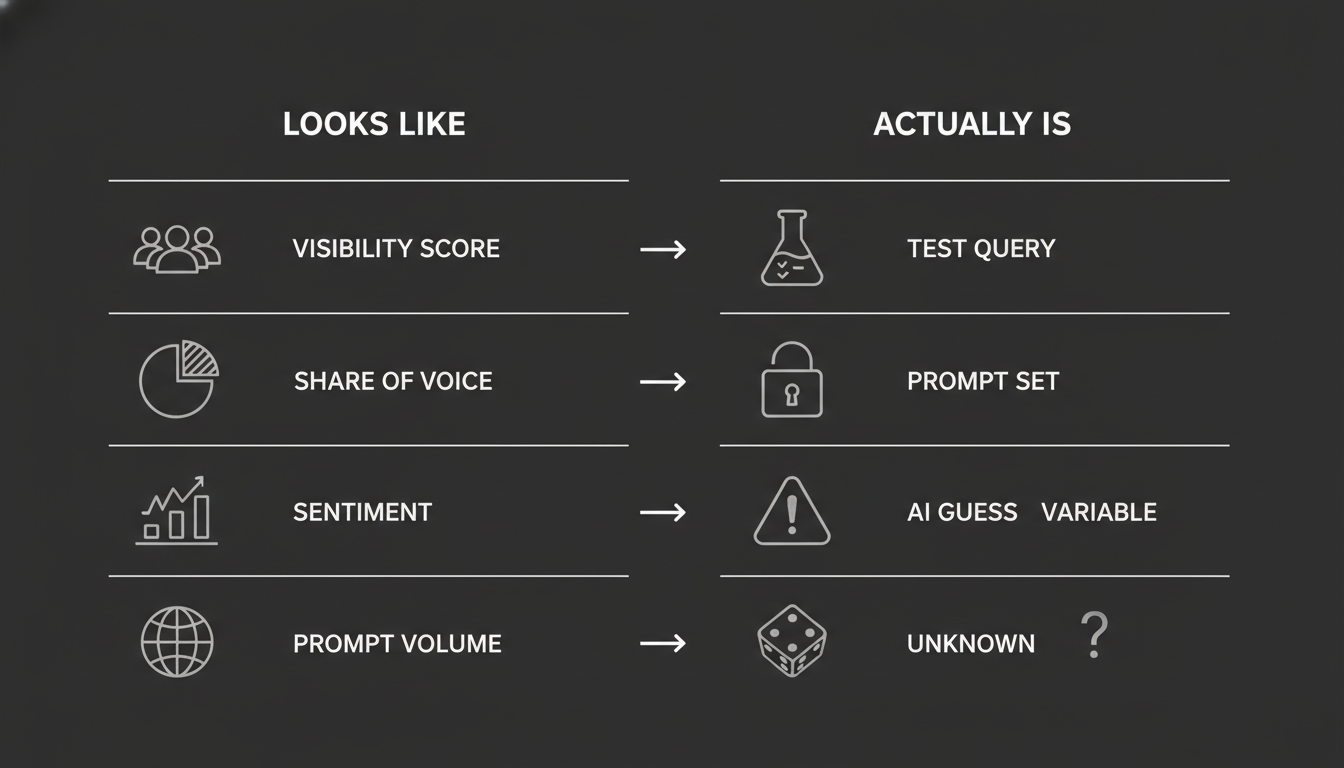
GEO metrics borrow language directly from SEO and analytics. Visibility. Share of voice. Rank. Sentiment. These words carry decades of meaning for marketers. They imply reach, exposure, audience behavior.
In GEO, they don't mean any of that.
An AI visibility score doesn't tell you how often users encountered your brand. It tells you how frequently your brand appeared across a vendor's selected prompt set. A citation count doesn't represent real conversations. Share of voice sounds global, but it only applies to a limited, proprietary slice of simulated queries.
Here's how the translation actually works:
AI Visibility Score sounds like how often users see your brand. It actually measures brand appearances across simulated prompts. Two different tools can show you opposite scores for the same brand on the same day.
Citation Count sounds like how often AI cites you in real conversations. It actually measures citations in test queries. There's no guarantee anyone saw them.
Share of Voice sounds like your percentage of all AI conversations. It actually measures your percentage of a controlled prompt set, implying global coverage that nobody can observe.
Prompt Volume sounds like how often users ask about something. It actually reflects frequency in a vendor's database, which may not reflect real behavior at all.
Sentiment Score sounds like user perception. It actually measures how AI describes your brand in tests. It can read as "positive" while being factually wrong.
Position or Rank sounds like a stable SERP ranking. It actually reflects how frequently your brand gets mentioned earlier in responses. AI answers aren't stable or repeatable.
None of these are bad metrics. But they're modeled indicators, not analytics. The distinction matters enormously when you're making budget decisions.
Why Does My GEO Dashboard Keep Changing When I Haven't Done Anything?
If you've looked at GEO data over time, you've probably noticed something unsettling. Scores move around. Sometimes a lot. Even when you haven't changed a thing on your site or in your content.
This isn't a bug in the tool. It's a property of AI systems themselves.
AI responses are non-deterministic. The same prompt can return different answers depending on model updates, temperature settings, session context, and subtle changes in phrasing. Your visibility score can shift because the model changed, not because your brand did.
Trying to treat GEO metrics like keyword rankings almost guarantees confusion. Keyword rankings exist in a relatively stable system. AI responses exist in a system designed to vary. That volatility isn't noise you should filter out. It's the actual behavior of the thing you're trying to measure.
This is one of the hardest adjustments for experienced marketers. You're trained to look for signal in movement. In GEO, some of that movement is just the system being itself.
So What Can I Actually Measure Right Now?
Once you accept the limitations, GEO becomes much easier to reason about. You just have to be honest about which column each metric belongs in.
Things you can actually track today: Referral traffic from AI platforms like ChatGPT, Perplexity, Gemini, and Copilot in GA4. Verifiable citations in AI responses. Directional patterns from large-scale prompt simulations. The accuracy of how AI describes your brand.
Things that rely on modeling or estimation: AI visibility scores. Share of voice. Prompt demand estimates. Sentiment analysis.
The mistake isn't using modeled data. I use modeled data. Every experienced operator does when direct measurement isn't available. The mistake is treating modeled data as if it were user behavior data. Those are fundamentally different things, and they support fundamentally different levels of confidence in your decisions.
What's Actually More Dangerous Than Being Invisible?
Here's something most people in the GEO conversation are missing entirely.
The biggest risk isn't that AI doesn't mention your brand. It's that AI mentions your brand incorrectly.
In practice, it's common to see tools report strong visibility or positive sentiment while AI models simultaneously hallucinate features, misstate pricing, or place products in the wrong category. I've seen this happen with SaaS companies where the AI confidently describes functionality that doesn't exist. The sentiment score reads positive. The visibility score looks great. And the actual content of what the AI is saying would send a prospect in the wrong direction.
For B2B companies especially, this kind of misrepresentation can damage trust faster than being absent altogether. A prospect who asks an AI about your product and gets wrong information doesn't just leave confused. They leave with false confidence. That's worse.
Visibility without accuracy isn't progress. It's risk.
Any GEO strategy that focuses solely on mentions without validating how a brand is being described is incomplete at best. For companies where trust and precision matter, I'd argue it's actively dangerous.
What Actually Influences How AI Models Talk About Brands?
Despite all the noise, we're not guessing blindly. Independent research consistently shows that AI models favor certain types of signals.
Off-site brand mentions and earned media carry big weight. Fresh content, updated within the last 12 months, matters. Clear structure, statistics, and quotations help. Consistent brand descriptions across the web make a difference.
Here's the part worth your attention: off-site mentions correlate more strongly with AI visibility than traditional SEO signals. That's a meaningful shift in where effort should go.
The good news is that many effective GEO tactics feel familiar. Structured content. Clear entity definitions. Readable formatting. Source attribution. GEO didn't invent these ideas. What GEO did is expose how directly they influence AI reasoning about your brand.
If you've been doing good content work for years, you're not starting from zero. The same principles apply. The mechanism through which they create value has just expanded.
How Do I Evaluate GEO Tools Without Getting Burned?
Given where the market is right now, skepticism is the right default. I don't say that to be cynical. The gap between what GEO tools can show you and what buyers expect them to show is wide enough to drive genuinely bad decisions.
The best way to evaluate any GEO tool or agency isn't by how impressive the dashboard looks. It's by how honestly they explain their methodology.
When someone makes bold claims about AI visibility, ask these questions:
How do you measure visibility? Is it simulation or real data? If they can't clearly explain the difference, that's your answer.
How do you account for AI variability? If they treat scores as stable metrics, they don't understand the technology they're selling.
What sample sizes do you use per topic? Small prompt sets produce noisy data. This matters more than most buyers realize.
How does this connect to business outcomes? Scores that don't link to traffic, accuracy, or conversions are interesting but not worth much.
How do GEO changes affect existing SEO performance? Anyone who treats GEO as completely separate from SEO is thinking about it wrong.
Vendors who understand GEO will answer these transparently. The ones who get defensive about methodology questions are the ones you should worry about most.
What's the Right Level of Investment for GEO Right Now?
For most companies, the smartest approach to GEO in 2025 and into 2026 is restrained rather than aggressive. I know that's not the exciting answer. But I've seen too many companies over-invest in emerging channels based on projections rather than current impact, and the correction is always painful.
Here's what a grounded approach looks like:
Improve content quality in ways that help both SEO and AI. Don't build a parallel GEO content strategy. Make your existing content clearer, better structured, and more consistently described across the web.
Build real brand authority through earned mentions. This was good strategy before GEO existed. It's better strategy now.
Use GEO tools for pattern detection, not promises. They're useful for spotting where AI gets your brand wrong, where competitors are being cited instead of you, and where your content gaps are. They're not useful as scorecards you report to your board.
Track real outcomes. Referral traffic. Content accuracy in AI responses. Conversions from AI-referred visitors. These are the things that actually matter.
Calibrate spend to current impact, not future hype. AI-driven discovery is growing quickly. But it hasn't replaced search, and it hasn't created a new analytics layer yet.
The Score Isn't the Point. Understanding Is.
GEO addresses a real shift in how people discover information. The question isn't whether this matters. It's whether you're measuring the right things and interpreting them correctly.
The most valuable thing right now isn't a higher visibility score. It's knowing what that score actually represents, where it's useful, and where it isn't.
The brands that win this shift won't be the ones chasing dashboards. They'll be the ones AI systems understand clearly, describe accurately, and trust enough to recommend.
That's not something you score once and move on from. It's something you build deliberately, over time, with clear eyes about what the data can and can't tell you.
How Akii Thinks About This Differently
Most GEO tools stop at visibility. They count mentions, score presence, and rank brands across simulated prompts. That information can be useful. But on its own, it misses the problem that matters most: how AI systems actually understand and represent your brand.
Akii was built around that gap.
Rather than treating AI visibility as a ranking problem, Akii treats it as a reasoning problem. The platform focuses on how models interpret your brand's category, features, positioning, and credibility signals, then surfaces where that understanding breaks down. This is why Akii evaluates not just whether a brand appears in AI responses, but what the AI is saying, whether it's accurate, and how that compares to competitors.
Akii is also explicit about the limits of the data. The platform doesn't claim access to real user conversations or global AI analytics. It uses large-scale prompt simulation to identify directional patterns, competitive differences, and misrepresentation risks, then translates those into concrete actions. You can see how this works on the features page.
In practice, this shifts the focus from "How visible are we?" to a more useful question: "Why do AI models trust certain brands enough to recommend them, and what signals are we missing?"
That's the question worth answering. And it's the one that actually leads somewhere.