
Why Most AI Monitoring Stops at Insight
Here's a pattern I've watched play out for over two decades, across every major technology shift: teams get access to better data, and then freeze.
It happened with web analytics. It happened with social listening. It's happening right now with AI visibility monitoring.
The tools have gotten genuinely good at showing you what's going on. You can see when an AI model starts fabricating your pricing. You can see when a competitor suddenly appears in recommendations where you used to be. Sentiment shifting from positive to neutral across multiple AI engines? Visible too.
But seeing the problem and fixing the problem are two completely different capabilities.
In traditional SEO, the signal-to-action path was relatively clean. Rankings dropped, you updated content, built links, adjusted metadata. There was a playbook everyone understood. AI search has shattered that simplicity. The signals are subtler, the causes less obvious, and there's no single corrective action for most issues.
What I see across teams right now is something I'd call dashboard paralysis. Perfect visibility into every problem, combined with total uncertainty about which problem to fix first. So what happens? Either nothing, or a flurry of random, untargeted tactics that burn time and budget without moving anything.
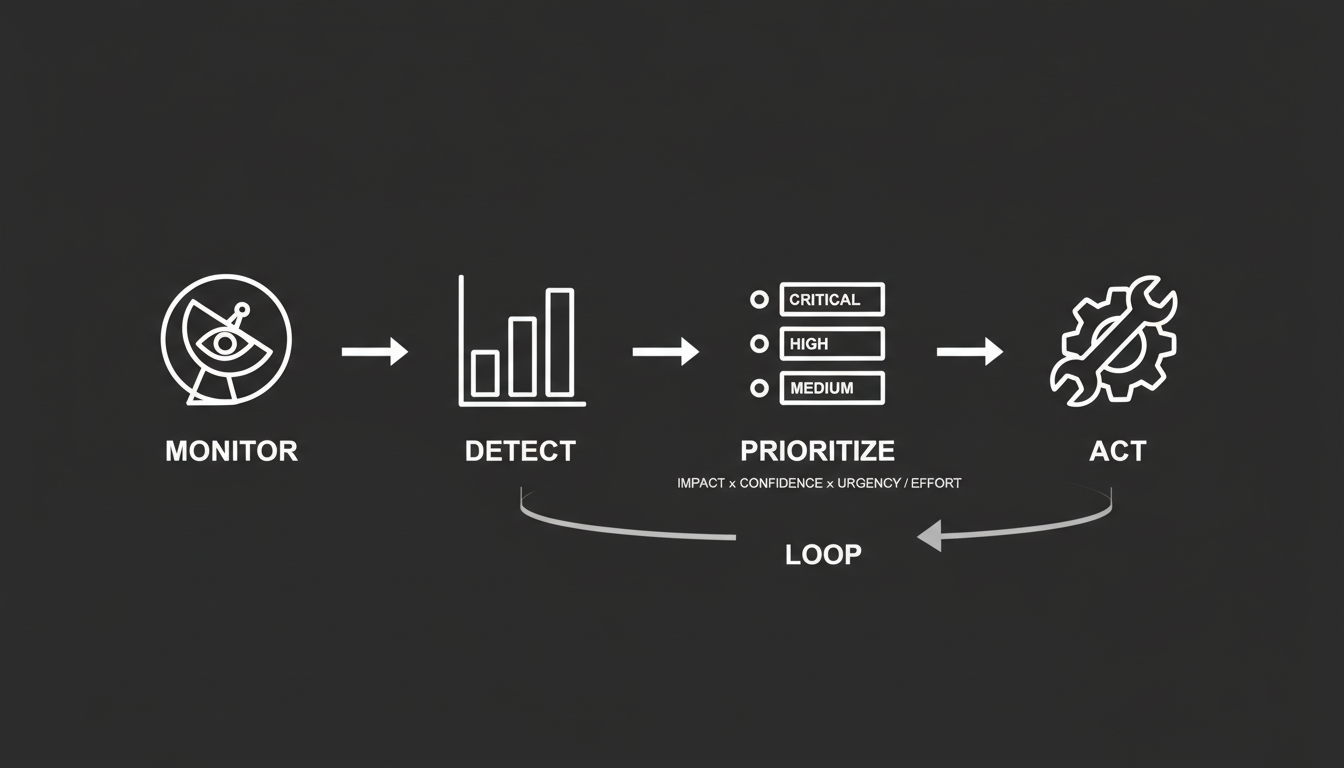
The uncomfortable truth: perfect monitoring is useless without a system for turning signals into prioritized action.
The Need for Deterministic Prioritization
So how do you break the paralysis? Remove emotion and panic from the equation.
When everything looks urgent, nothing gets fixed. I've seen this in every operational context I've worked in. The teams that execute well aren't the ones with the most data. They're the ones with the clearest system for deciding what to do next.
For AI visibility, that means scoring every issue against a small set of variables that force a rational ranking. Every issue gets evaluated on four dimensions.
Impact measures commercial damage. If an AI engine is telling potential customers your enterprise software costs a fraction of what it actually does, that's a revenue problem. It scores high. If a minor product feature is being described slightly inaccurately, that scores lower.
Confidence asks whether you're looking at a real trend or a one-off glitch. A single weird response from one AI model on one day is noise. Your brand disappearing from recommendations across three different AI engines consistently over two weeks is a pattern. Weight so.
Urgency captures how fast the problem is spreading. A competitor slowly publishing new comparison articles is a slow burn. A viral Reddit thread full of negative reviews getting ingested by AI models in real time is a wildfire. Speed of spread determines how quickly you need to respond.
Effort acts as a reality check. Adding structured schema data to a webpage might take a day. Launching a multi-month PR campaign to earn high-authority citations takes months and large budget. Dividing by effort keeps your priority list grounded in what's actually executable with the resources you have.
The formula: Impact times Confidence times Urgency, divided by Effort.
What comes out is a ranked list. Not a dashboard full of red alerts. Not a wall of metrics that all feel equally important. A clear sequence: fix this first, then this, then that.
This is the kind of deterministic prioritization that Akii builds into its approach to AI visibility monitoring. Not because scoring formulas are exciting, but because without them, teams stay stuck.
Separating Diagnosis From Recommendation
Here's where people get it wrong most often.
AI tools are excellent detectives. They can identify that Gemini has started categorizing your product as suited only for small businesses. They can flag that ChatGPT is citing a competitor's whitepaper as the authoritative source in your category. They can detect that Perplexity has stopped mentioning your brand entirely for a query cluster you used to own.
That diagnostic capability is genuinely valuable. But there's a line that has to be drawn.
AI should diagnose. Humans should decide what to do about it.
Why? Because the appropriate response to an AI visibility problem depends on context no monitoring tool fully understands. Your product roadmap, your competitive positioning, your available resources, your risk tolerance. These are judgment calls.
What works in practice is mapping diagnoses to a predefined playbook. When a specific type of problem is detected, the corresponding response should already be defined. Not invented on the fly. Not debated in a meeting. Already mapped, waiting.
Think of it like an incident response system. The monitoring layer tells you what happened and why. The playbook tells you what to do. The prioritization formula tells you when.
This separation prevents two failure modes I see constantly. First, teams that treat every AI visibility issue as a unique crisis requiring custom strategy. Second, teams that let the AI tool itself recommend actions, which often lack the business context to be useful.
An AI brand audit gives you the diagnostic layer. The prioritization system gives you the sequencing. The playbook gives you the response. These are three distinct functions, and collapsing them together is how teams end up overwhelmed.
Converting Deltas Into Backlog
Stop looking at static snapshots. Start looking at changes over time.
A dashboard showing your current AI visibility score is interesting. A system showing your visibility dropped 15% in the last two weeks is something you can act on. The delta is what matters, not the number.
When you track deltas and score them through a prioritization formula, what you get is a structured backlog. Issues ranked by severity, each with a clear response type. Here's how that breaks down in practice.
Critical Severity: Technical Failure
This is when AI engines have fundamentally wrong information about your business. Fabricated pricing. Complete misunderstanding of what your company does. Factual errors that directly cost you revenue.
The response here is not content creation. It's a full technical audit and deployment of machine-readable structured data. Schema markup that gives AI models accurate, unambiguous facts they can't misinterpret. You're correcting the source material, not trying to outpublish the error.
This is where tools like a website optimizer become essential. If your site isn't giving AI engines clean, structured data to work with, you're leaving your brand narrative up to whatever the model infers from scattered sources.
High Severity: Competitive Displacement
A competitor's share of voice jumps 25% overnight. This doesn't happen randomly. It means the AI has found new, more trusted sources that favor the competitor.
The instinct is to start creating content immediately. That's the wrong first move.
Do citation analysis first. Figure out which new sources the AI is drawing from. Then build a campaign to earn your brand's presence in those same sources. You're not fighting the AI. You're feeding it better inputs.
Medium Severity: Narrative Drift
Brand sentiment weakens from positive to neutral over several weeks. Not a crisis, but a trend that compounds if ignored.
What's usually happening is that the AI is picking up stale or slightly negative user-generated content. Old reviews, outdated forum posts, comparison articles nobody has updated in two years.
The response is to audit review velocity across the platforms that feed into AI models, then initiate a campaign to generate fresh, positive signals. Not fake reviews. Real customer advocacy, directed at the right platforms.
Each severity tier has a different response type, a different timeline, and a different resource requirement. That's the whole point. Without this structure, every issue gets the same panicked reaction, which means none of them get the right one.
Closing the Loop
Everything I've described is useless if it runs once.
The real value comes from repetition. This is a loop, not a project.
Monitor continuously. Detect meaningful changes. Prioritize using the formula. Act with targeted fixes. Validate that the fix worked in the next data snapshot. Repeat.
Each cycle does two things. It fixes the immediate problem. And it makes the system smarter. You learn which response types work for which severity tiers. You calibrate your scoring as you see results. You build institutional knowledge about how AI engines respond to different interventions.
There's a compounding effect here that most people underestimate. Every time you successfully correct an AI's understanding of your brand, you're building trust in the model's training data. Over time, your brand becomes the default trusted source. That's not a metric on a dashboard. That's a competitive position that gets harder to displace the longer you hold it.
Which means the inverse is also true. Brands that start this process late will find the gap increasingly difficult to close. The early movers aren't just fixing problems. They're building a compounding advantage with every cycle.
This is the shift I keep coming back to in my work with Akii. AI visibility isn't a passive metric to report on quarterly. It's a dynamic system that has to be actively engineered. The difference between brands that win in AI search and brands that lose comes down to one question: are you watching what AI says about you, or are you deliberately shaping it?
The monitoring tools exist. The metrics frameworks exist. The prioritization logic exists. What's missing for most teams is the commitment to run the loop.
Start the loop. Run it consistently. Let it compound. That's the entire strategy.